АСУ ТП: как создавалась система для точного расчета наработки станков большого завода
| Автор | Сообщение |
|---|---|
 admin
admin
|
|

|
Суть задачи очень простая: есть много очень дорогого оборудования, которое требует регулярных технических осмотров и своевременного обслуживания. Последние лет десять оборудование обслуживалось, например, раз в полгода, раз в три месяца и так далее, без корреляции со временем фактической наработки. Смысл был в том, что если на оборудовании произойдёт авария, и при этом оборудование по факту наработало срок больший, чем положено до обслуживания — руководитель сядет.
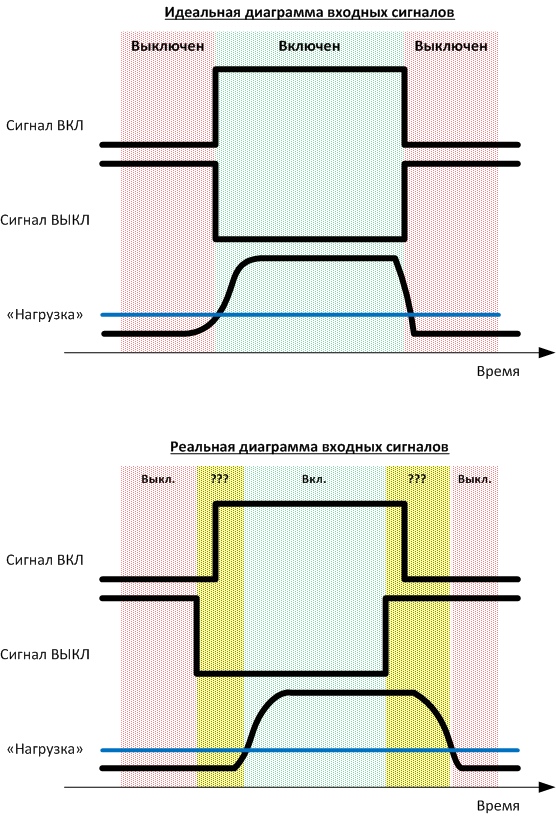
Особенности формирования сигналов (задержек локальных сигналов автоматики) в системе управления, это создает некоторые трудности при расчете наработки.
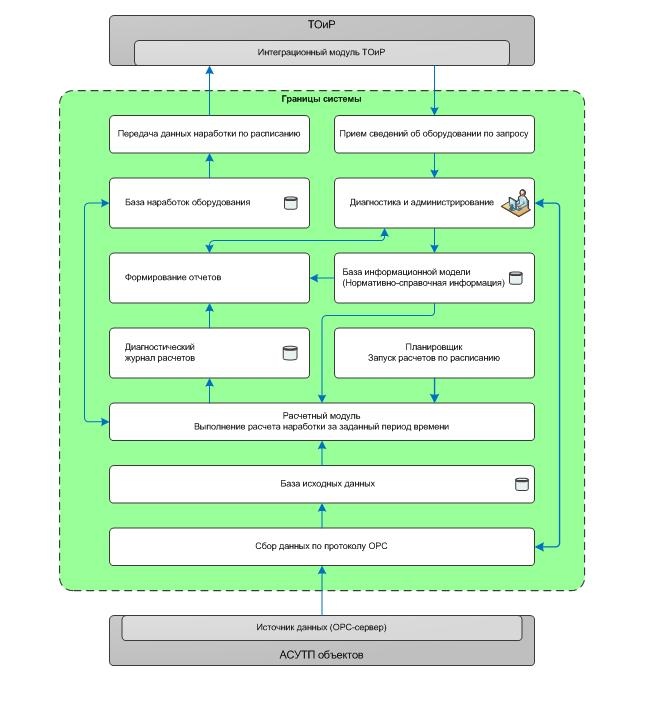
На высокотехнологичных производствах один из методов – поставить специальный контроллер на каждый технический объект, требующий учета его наработки. Это достаточно дорого. Есть станки и прочее высокотехнологичное оборудование, которые считают сами, важно просто правильно забирать данные. В нашем случае учет наработки велся вручную, в журнал с помощью механика типа «станок проработал 3 дня плюс-минус 4 часа». В итоге было принято решение подцепиться к управляющему софту и снимать данные с него. Сейчас расскажу, что случилось дальше и какое к этому имеет отношение картинка выше. Архитектура
Например, на картинке до ката вы видите самый простой случай того, как служебная сигнализация (два бита – сигнал «ВКЛ» и сигнал «ВЫКЛ») внезапно превращаются из триггера в нечто куда более монструозное. Такова жизнь. И считать наработку станка приходится уже не по данным сигналам, а (в этом конкретном случае) по нагрузке. Были и другие ситуации веселее, но, увы, углубляться не имею права, уж больно специфическое производство. Как шла работа Схема расчёта есть выше; в целом это известный технический процесс, который в виде абстракций поддерживается 4 разными производителями промышленного софта (в том числе есть опенсорсное решение), но, как обычно – когда речь заходит о конкретном объекте, нужна доработка напильником. Мы создали не только общую архитектуру, но и конкретные алгоритмы коррекции данных, поскольку, как я уже говорил, особенности работы систем управления таковы, что способны с корнем поломать всю логику софту. Здесь нужно пояснить, что данные о состоянии оборудования поступают в виде трех сигналов – сигнала «включено», сигнала «выключено» и текущей нагрузки оборудования. Для нагрузки задается пороговое значение, при превышении которого считается, что оборудование включено и работает на номинальном режиме. В идеале эти сигналы должны изменяться согласовано друг с другом. Но реальность оказалась такова, что сигналы изменяются не всегда так, как это ожидалось. Что создает дополнительные трудности. Плюс надо было добавить часть сигналов, поскольку они были плохо описаны, отличались в реализации или изначально не поддерживались протоколом. Затем потребовалось восстановить исторические данные на случай сбоя связи между компонентами системы и разработать схему расчёта наработки при длительном обрыве этой связи. Мы фиксировали, пересчитывали и создавали инструменты для учета таких ситуаций. Сложность в том, что при физическом обрыве связи мы просто не видели событий, но не знали про сам факт потери сигнала. Таковы особенности протокола. В результате на уровне системы АСУ ТП пришлось создать «пульс» — некую виртуальную задвижку, которая сдвигалась раз в секунду. Благодаря этому «датчику» мы знали, что сигнал идёт. Если он «щёлкал» неправильно или с искажениями – мы отмечали период как недостоверный. Если по недостоверному периоду восстановить данные из логов (или пересчитать руками) было нельзя– то уровнем выше он, скорее всего, отмечался как наработка, поскольку основная задача – не перешагнуть за предел без ТО.
Дополнительную сложность вносили проблемы с передачей данных, что отражалось на их доступности и качестве. При кратковременном пропадании связи с источником данных можно сделать обоснованное предположение, что состояние оборудования не изменялось на этом отрезке времени, но при длительном отсутствии данных состояние оборудования могло измениться, и в этом случае система не может дать однозначного ответа на вопрос – что происходило за то время, за которое данные отсутствуют. В результате реализации проекта были выработаны и согласованы с заказчиком алгоритмы, способные обрабатывать эти и другие нестандартные ситуации.
В результате сейчас точность — до долей секунды, что очень и очень круто и для нас, и для производства. Следующий шаг — проверка масштабируемости уже без нашего непосредственного участия, самостоятельно силами диспетчеров. На конкретном производстве станок начинает опрашиваться сразу после появления в SAP. В целом, такие системы можно строить вообще не трогая ERP — у нас, как видите, в системе есть свои отчёты. Просто в данном случае заказчику удобнее перераспределять и нагрузки, и ремонты именно в ERP. По ходу пьесы, кстати, пару раз менялись требования к передаче данных ТОиР — но у них шёл плановый апгрейд, и это, в целом, нормально. Конечно, очень здорово, что мы вообще не лезли на нижний уровень, где идёт служебная сигнализация до физических узлов – это сделало проект куда дешевле типовых подобных. Результат сложно оценить в деньгах, но заказчик точно знает, что уже не будет бесполезных ремонтов по планам. Резюме Но в целом подобные вещи можно делать также на базе решений от таких вендоров как WonderWare (платформа Wonderware System Platform), Iconics (платформа ICONICS Genesis), Tibbo (тайванско-российский вендор, платформа называется Aggregate). Но главная особенность, конечно, в том, что для успешного завершения проекта крайне желательно наличие опыта алгоритмизации не всегда полных и согласованных данных служебной сигнализации, плюс фактического опыта работы с крупным производством. Повторюсь, на наших объектах уже были ТОиР-модули. Но в целом это не обязательно, например, вместо выгрузки данных в них можно пользоваться и нашими веб-отчётами (пользователь может мониторить состояние системы, формировать отчеты, принимать и загружать данные, контролировать наличие тегов для сбора, выполнять ручные отправки и настраивать систему) — эта часть решения создана на Microsoft .NET Framework на основе ASP.NET, язык C#. Front-end — на HTML5. Итог:
В общем, мы поставили свой сервер рядом с их серверами, а они получили точные расчёты по наработке станков. Дальше — куча всего по консолидации данных, их обработке и т.п., — в общем, детективы и алгоритмизация. Итог — точный источник данных про наработку, который взаимодействует с положенными системами автоматизации производства и управления предприятием. Было много боли, связанной с тем, что это всё-таки большая производственная группа с положенными бюрократическими особенностями, но это по нашим проектам, скорее привычный рабочий процесс. Сюрпризов, в общем, не было, если не считать ряд показаний оборудования и отсутствие в ряде случаях техдокументации, которую, фактически, надо было реверсить – но это предполагалось ещё в самом начале. Источник: https://habr.com/company/croc/blog/266007/ |
| Сообщения: 463 | |